Batting Average Prediction Via Machine Learning
Motivation:
The goal of this project was to use machine learning to predict a Major League Baseball player’s season long batting average given their previous year’s statistics. Every year, general managers are faced with difficult decisions about which players to sign, which to let go, and how much to pay them. Millions dollars are on the line. The ability to empirically predict a player’s batting average, a standard measure of performance, is an extremely useful tool for these general managers.
Data Set and Attributes:
The following 9 attributes were used to build the model. All attributes are numerical and are for the year prior to the one being predicted:
* Year
* Games Played (G)
* At-Bats (AB)
* Runs Batted In (RBI)
* Walks (BB)
* Strike-outs (SO)
* Salary
* Age
* Batting Average
Data was collected from seanlahman.com and includes statistics from 1990 through 2014. Additional data was available for earlier years, but the decision was made to focus on “modern” years as the game of baseball has changed throughout it’s history. The training dataset includes 19,522 entries with an additional 2,161 entries held out for final model verification.
Baseline Accuracy:
In order to judge model accuracy, a baseline needed to be determined. In a case where the output is nominal, this would be done by calculating the accuracy when the most common attribute is chosen for each entry. Since this experiment has a numerical output, the baseline was derived off the assumption that a player would have the same batting average as the previous year. This is a very rough estimate of performance, but follows a reasonable expectation and provides a useful baseline for gauging model performance. Using this estimate the mean absolute error for each dataset was calculated:
--> Training Data: .067
--> Held Out Data: .066
Models:
Several types of models were tested before deciding on the final model. All models were built using 10-fold cross-validation on the training set and verified against the held out set. The first was a basic linear regression model. With default settings in Weka, the model predicted batting averages with a mean absolute error of .072 on the training data, and .0718 on the held out data. Despite tuning parameters, linear regression continued to perform worse than the baseline and was thus discarded.
The second model was M5P. This model combines elements of decision trees and linear regression. A small decision tree is created with each leaf containing its own linear regression model. The tuned M5P model achieved a 10-fold cross-validation mean absolute accuracy of .057 on the training set, and .058 on the held out data. This shows a significant improvement of 10 and 8 points respectively.
The final model tested was a multilayer perceptron model. The best results achieved were using a 10 layer model with a learning rate of .1. Further decreasing the learning rate degraded accuracy. This model performed slightly better than the M5P model with a training accuracy of .055 and held out accuracy of .056.

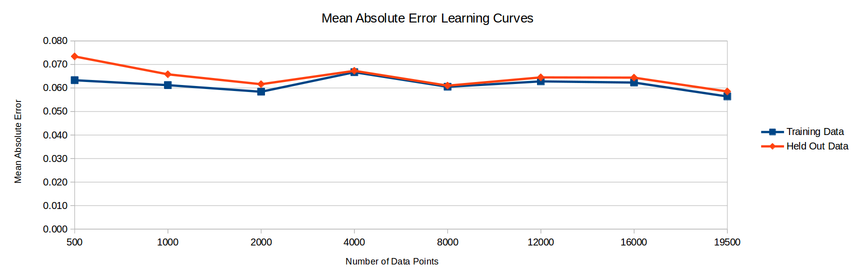
Attribute Analysis:
It was attempted to further improve upon these results by analyzing the nine attributes and removing extraneous ones. Using Weka’s CfsSubsetEval attribute analyzer, it was found the the attributes most strongly correlated to the next year’s vatting average were:
* Year
* At Bats
* Age
* Current Batting Average
However, removing other attributes resulted in no improvement of the models over those built using all the attributes. In most cases, the absolute mean error often increased. This implies that while the four attributes selected may have more information gain, none of the attributes are completely irreverent for this project.
Analysis of Results
Ultimately, the multi-layered perceptron had the best performance with a learning rate of 0.1. This model had the lowest absolute mean error, and was significantly lower than the absolute mean error of the baseline. This means that the multi-layered perceptron model most accurately predicted the next years batting average for each player based on the stats of the year before. Specifically, the model had an absolute mean error of 0.0545 for the training and validation data, and 0.0562 on the held out data.
Future Work:
There are a few potential area for future work in this project. Obviously more work can be done on refining the models and improving accuracy. Additionally, the models from this project could be used to make predictions about current MLB players and at the end of the season, the actual statistics could be compared to those predictions.
Additionally, it is conceivable that the approach from this project could be applied to other statistics in baseball. For instance, models could be created to predict other attributes used in this project such as RBI’s or Strike-Outs.
Group Member Participation:
Tim - Data Processing, Model Evaluation, Report Writing
Mikhail – Data Analysis, Website Building
Nathan – Data Analysis, Attribute Analysis, Report Writing